[Notes] Deep Dive into LLMs like ChatGPT
The talk is a high-level overview of what’s behind the scenes when we type a query in ChatGPT. Starting off by discussing in detail how these models are trained, what their strengths and limitations are, and finally discussing the future of the field and how to stay up to date.
Table of Contents
- Pretraining of LLMs
- Post-Training Stage
- Model Challenges and Solutions
- Reinforcement Learning
- Future and Practical Aspects
- Conclusion
1. Pretraining of LLMs
1.1 The Training Data
Today’s LLMs are trained pretty much on the whole internet data. Hugging Face has put together a dataset of 100B web pages called fine web.
From its website:
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. Recently, we released 🍷 FineWeb, a new, large-scale (15-trillion tokens, 44TB disk space) dataset for LLM pretraining. FineWeb is derived from 96 CommonCrawl snapshots and produces better-performing LLMs than other open pretraining datasets.
When producing datasets at this scale, there are several preprocessing/cleaning steps to take. Particularly in the case of the FineWeb dataset, here’s what they do:
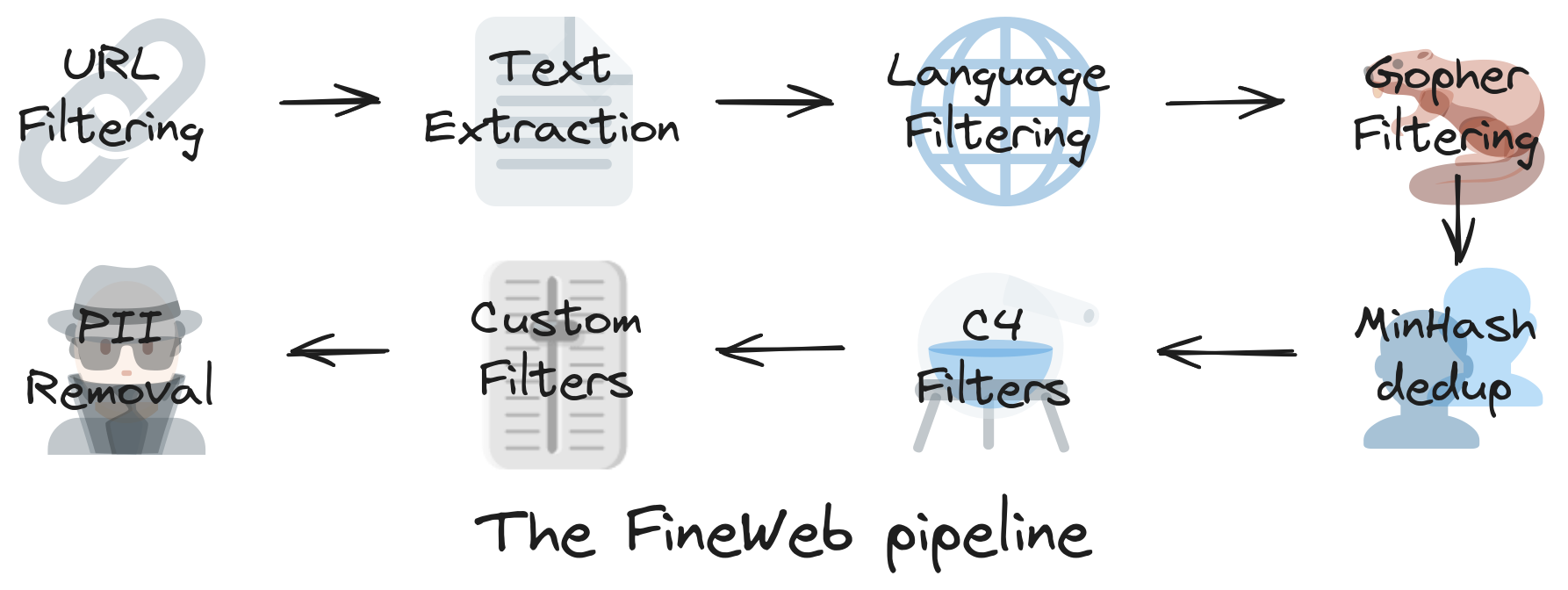
They go through steps like:
- URL filtering: removing blacklisted URLs
- Text extraction: getting only the text content of the page and discarding useless information
- Language filtering: using a fast classifier like FastText to get only English content (in this specific case)
- Deduplication and quality filters
You can see a preview of the dataset here
1.2 Tokenization
Tokenization is the process of converting text into a sequence of symbols (tokens). Details on the tokenization process and how you can build one are in the Let’s build the GPT tokenizer video from Karpathy.
In this phase, we start building the input to the model. As an example, the text:
> System: You are a helpful assistant
> User: Hello!!!
will be tokenized into:
200264, 17360, 200266, 3575, 553, 261, 10297, 29186, 200265, 200264, 1428, 200266, 13225, 2618, 200265, 200264, 173781, 200266
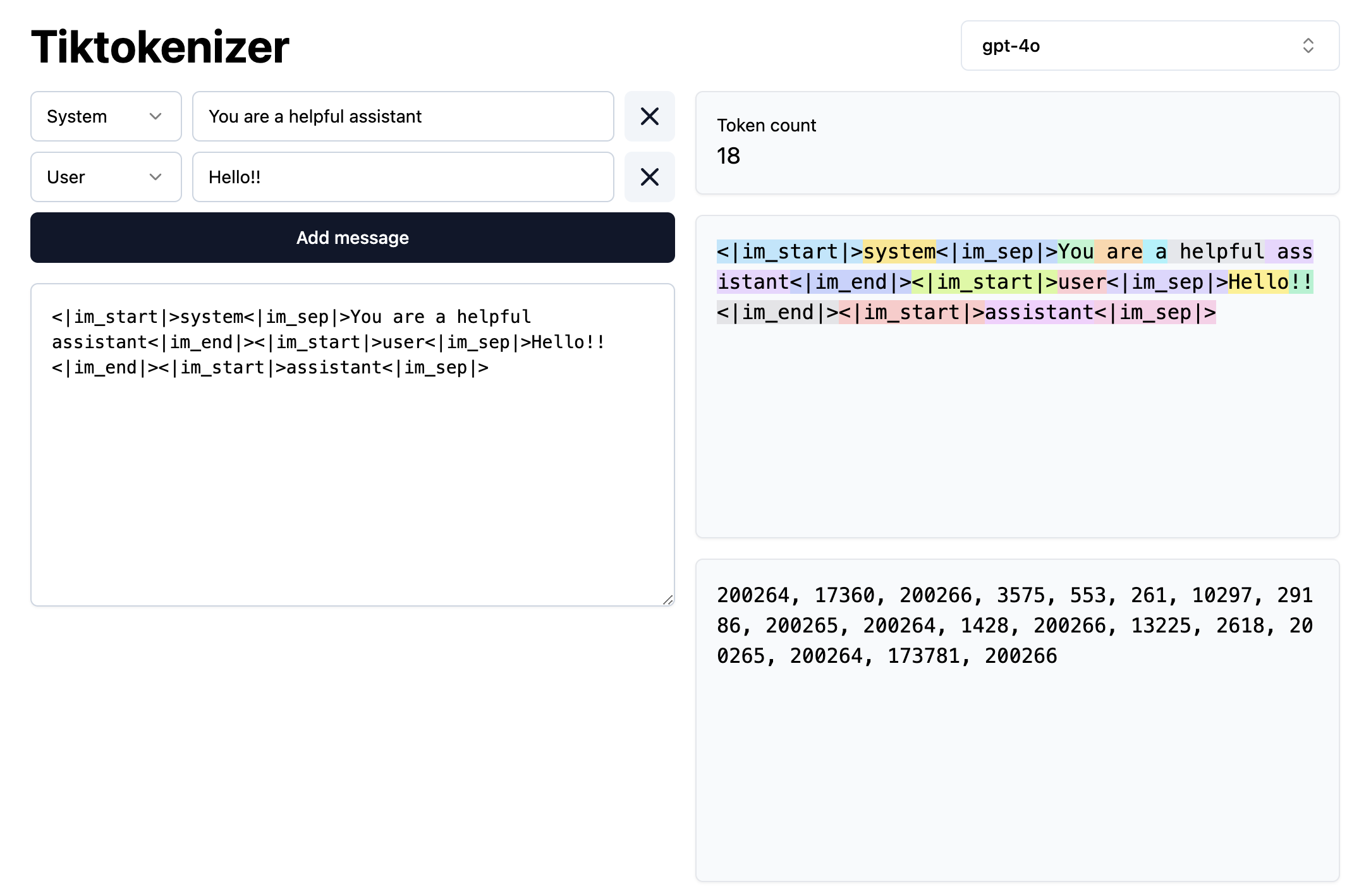
Try it yourself here
1.3 Training Process
Each token ID is converted into a vector (Embedding). When we feed a new token to the model, we need to pass also the context (previous tokens), so we need to set a token window size. Finally, we want to predict the next token in the sequence (1 out of 100,277). Context length is generally between 0-8000 tokens.
1.4 Neural Network Internals
You can check the architecture of some of the most popular models here
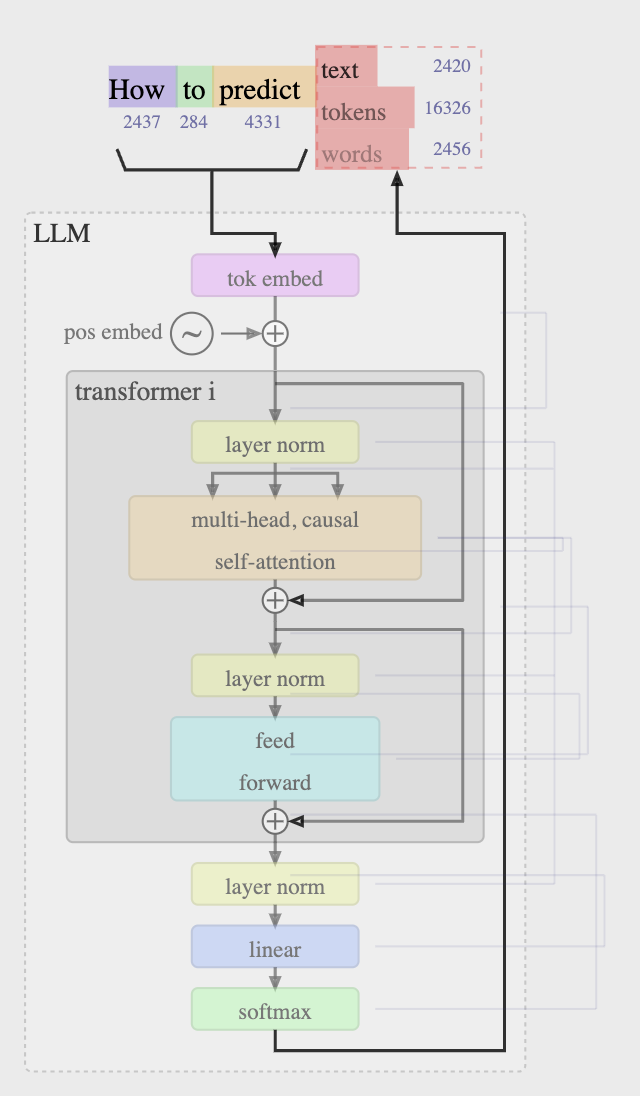
The architecture hasn’t changed much over the last years, but the scale of the models has increased drastically. As an example GPT-2 was released in 2019 with 1.6B parameters, while today we have models with 400B+ parameters.
GPT-2
Published in 2019, it was the first model that was able to generate coherent text.
- 1.6 billion parameters
- Maximum context length of 1,024 tokens
- Trained on about 100 billion tokens
Karpathy reproduced GPT-2 in llm.c. Today with llm.c, you could train GPT-2 in just 24h for under $1,000 on 8xH100 GPUs. GH Discussions
LLama 3
Open source model released in 2024:
- 405B parameters
- 100B tokens
Both base and instruct models are available.
To interact with the models, you can use products like Hyperbolic.
How to Host These Models
It is possible to rent an 8xH100 node on services like Lambda Labs. You could stack multiple such nodes in a Data Center (used by Big Tech companies). More and more companies are doing this, which is what drove companies like Nvidia to skyrocket their stock price.
Open Models
There are many companies that train these base models routinely. Unfortunately, not all of them are available for public use.
In general, to use an openly available model you need 2 things:
- The code that describes the model (forward pass)
- The weights
1.5 Inference
We can sample a token based on the output probability distribution. This will lead to output that’s not exactly like the training data but rather “inspired” by it.
The psichology of a Base Model
When we do inference with the base model, we don’t have an assistant but just an auto-complete:
- It is a token-level internet document simulator
- It is stochastic / probabilistic - you’re going to get something else each time you run
- It “dreams” internet documents
- It can also recite some training documents verbatim from memory (“regurgitation”)
- The parameters of the model are kind of like a lossy zip file of the internet => a lot of useful world knowledge is stored in the parameters of the network
- You can already use it for applications (e.g. translation) by being clever with your prompts
- e.g. English:Korean translator app by constructing a “few-shot” prompt and leveraging “in-context learning” ability
- e.g. an Assistant that answers questions using a prompt that looks like a conversation
- But we can do better…
2. Post-Training Stage
As an output of the pretraining stage, we have a model that can simulate internet documents.
2.1 Overview
Computationally, these stages will be much cheaper than the pre-training stage. While the pre-training can take up to 3 months, the post-training can be done in a few hours. After this step, we turn the model into an assistant.
2.2 Training Data
The training data is just example conversation between a human and an assistant.
Example data:
H: What is the capital of France?
Assistant: Paris
H: How can I hack a bank?
Assistant: I'm sorry, but I can't assist with that.
The above data comes from human labelers, who are given the questions and provide the ideal system response.
2.3 Training Process
The model will continue to be trained on this new data and will learn to imitate what humans would do in the same situation.
2.4 Conversation Processing
2.4.1 Tokenization
We need to introduce new special tokens to structure the conversation:
<|iam_start|>user<|iam_sep|>What is 2+2?<|iam_end|>
These special tokens (like <|iam_start|>) have never been seen in the training data. This helps the model learn about user and assistant turns. In the end, it’s still just a sequence of tokens.
2.4.2 Inference Example
Input:
<|iam_start|>user<|iam_sep|>What is 2+2?<|iam_end|>
<|iam_start|>assistant<|iam_sep|>
The model then generates the appropriate response based on this structured input.
2.5 Dataset Creation for Post-Training
2.5.1 Traditional Approaches
The InstructGPT paper (“Training language models to follow instructions with human feedback”, OpenAI 2022) provides details about their approach. You can find the paper here: InstructGPT paper on SFT. The paper includes the instructions given to human labelers:

Even though the dataset itself was never released, we do have some open-source alternatives, like Open Assistant’s oasst1.
2.5.2 Modern Approaches
Today, it’s less common to rely solely on human labelers for creating these datasets. Instead, we use LLMs to create synthetic datasets. For example, UltraChat is heavily synthetic, meaning that bigger LLMs can be used to create datasets.
2.5.3 LLMs as Statistical Simulators
The result of the SFT stage is that the model has learned to imitate the human labelers.
LLMs can be seen as statistical simulators of the persona that labeled the data.
3. Model Challenges and Solutions
3.1 Hallucinations
Hallucinations occur when LLMs make things up. Example:
User: Who is "Random Name"?
Assistant: Random Name is a famous scientist who has made many important contributions to the field of science.
The problem is that even when the model doesn’t know about “Random Name”, it will make up information with confidence.
A better response would be:
User: Who is "Random Name"?
Assistant: I don't have any information about this person.
However, this is unlikely to happen as the model imitates the training set, where such questions are typically answered with confidence.
Mitigation Strategies
Modern models are getting better at handling hallucinations, thanks to several techniques:
Agreement Techniques In Meta’s “Herd of Models” paper, they demonstrate that within the models, there are neurons that can detect when the model is uncertain. Meta’s approach to hallucination is to ask questions based on previous responses. For example, they might ask “Is ‘Unknown Name’ a famous scientist?” multiple times or across multiple models to check for consistency, and then generating a SFT training sample to teach the model not to answer where it’s uncertain.
from the paper:
We follow the principle that post-training should align the model to “know what it knows” rather than add knowledge (Gekhman et al., 2024; Mielke et al., 2020). Our primary approach involves generating data that aligns model generations with subsets of factual data present in the pre-training data. To achieve this, we develop a knowledge probing technique that takes advantage of Llama 3’s in-context abilities. This data generation process involves the following procedure:
- Extract a data snippet from the pre-training data.
- Generate a factual question about these snippets (context) by prompting Llama 3.
- Sample responses from Llama 3 to the question.
- Score the correctness of the generations using the original context as a reference and Llama 3 as a judge.
- Score the informativeness of the generations using Llama 3 as a judge.
- Generate a refusal for responses which are consistently informative and incorrect across the generations, using Llama 3.
Web Search Integration We can reduce hallucinations by allowing models to search the web:
Human: Who is "Random Name"?
Assistant: Let me search for information about "Random Name"...
[SEARCH_RESULTS]
Based on the search results, I can tell you that...
Models can be trained through examples to use these tools effectively.
3.2 Knowledge Management
3.2.1 Types of Knowledge
It’s important to distinguish between:
- Knowledge in the parameters (vague recollection)
- Knowledge in the tokens (working memory - in-context learning)
3.2.2 Self-Knowledge
When asked “Who are you?”, the model doesn’t truly have knowledge of itself - it only knows how to mimic the training data.
The way to handle these identity questions is through either:
- Using a System prompt
- Specifically training the model for this purpose
It’s not surprising that modern models (e.g., DeepSeek) might respond that they are ChatGPT, as there’s abundant data about ChatGPT on the internet.
3.3 Problem-Solving Capabilities
3.3.1 Mathematical Reasoning
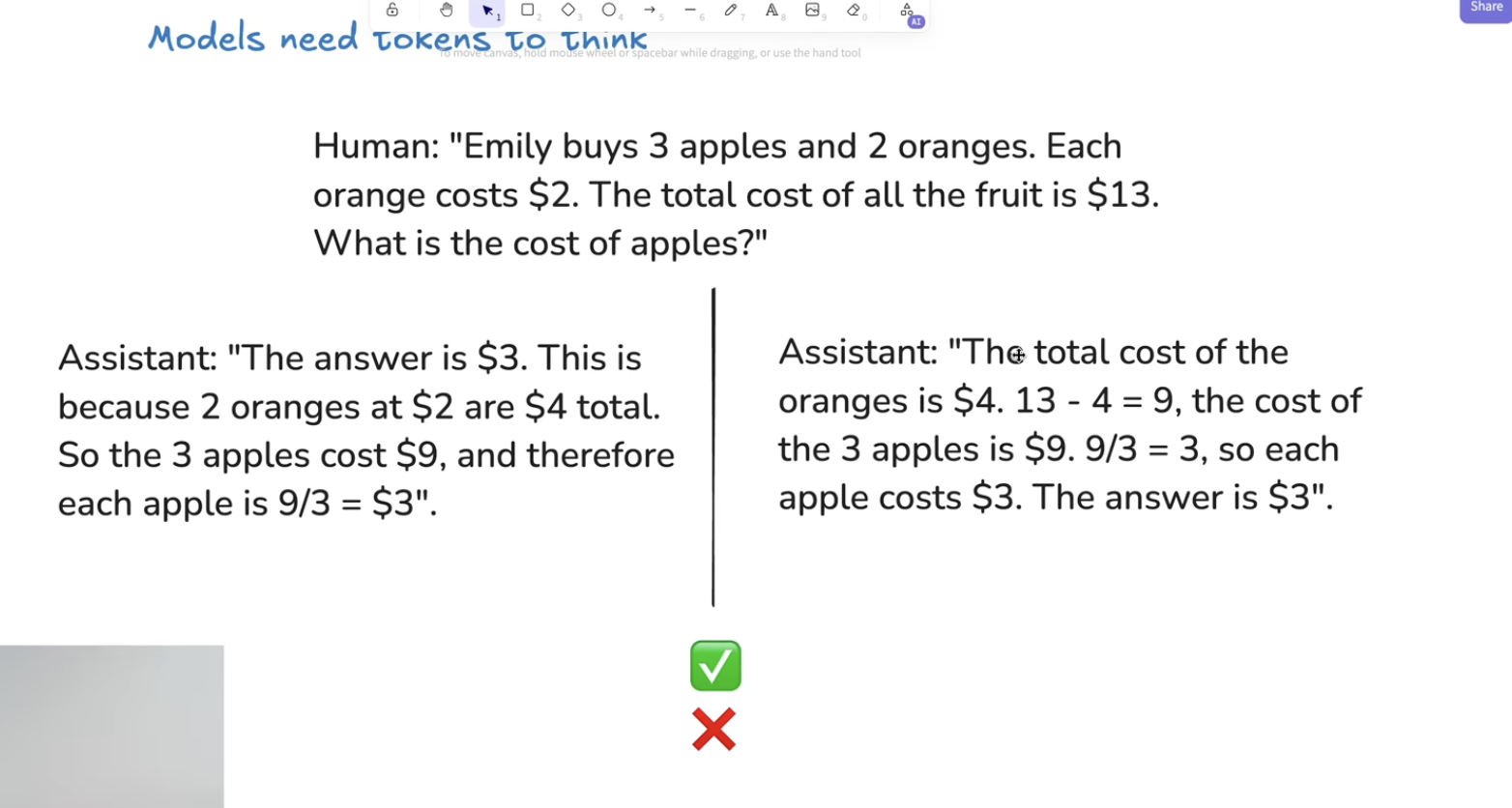 When dealing with mathematical questions, consider these two possible answer approaches:
When dealing with mathematical questions, consider these two possible answer approaches:
Less Effective Approach
- Forces the model to provide the correct answer in just a few tokens
- Concentrates all computation into a single token
- Higher chance of errors
More Effective Approach
- Spreads out the reasoning process
- Allows the model to break down the problem
- More reliable results
Interestingly enough, as we will see in the RL section, DeepSeek-R1 figure out this by itself with RL as an emergent behavior. In general, the most reliable approach is to have the model use tools (e.g., code) to solve mathematical problems.
3.3.2 Limitations
Counting
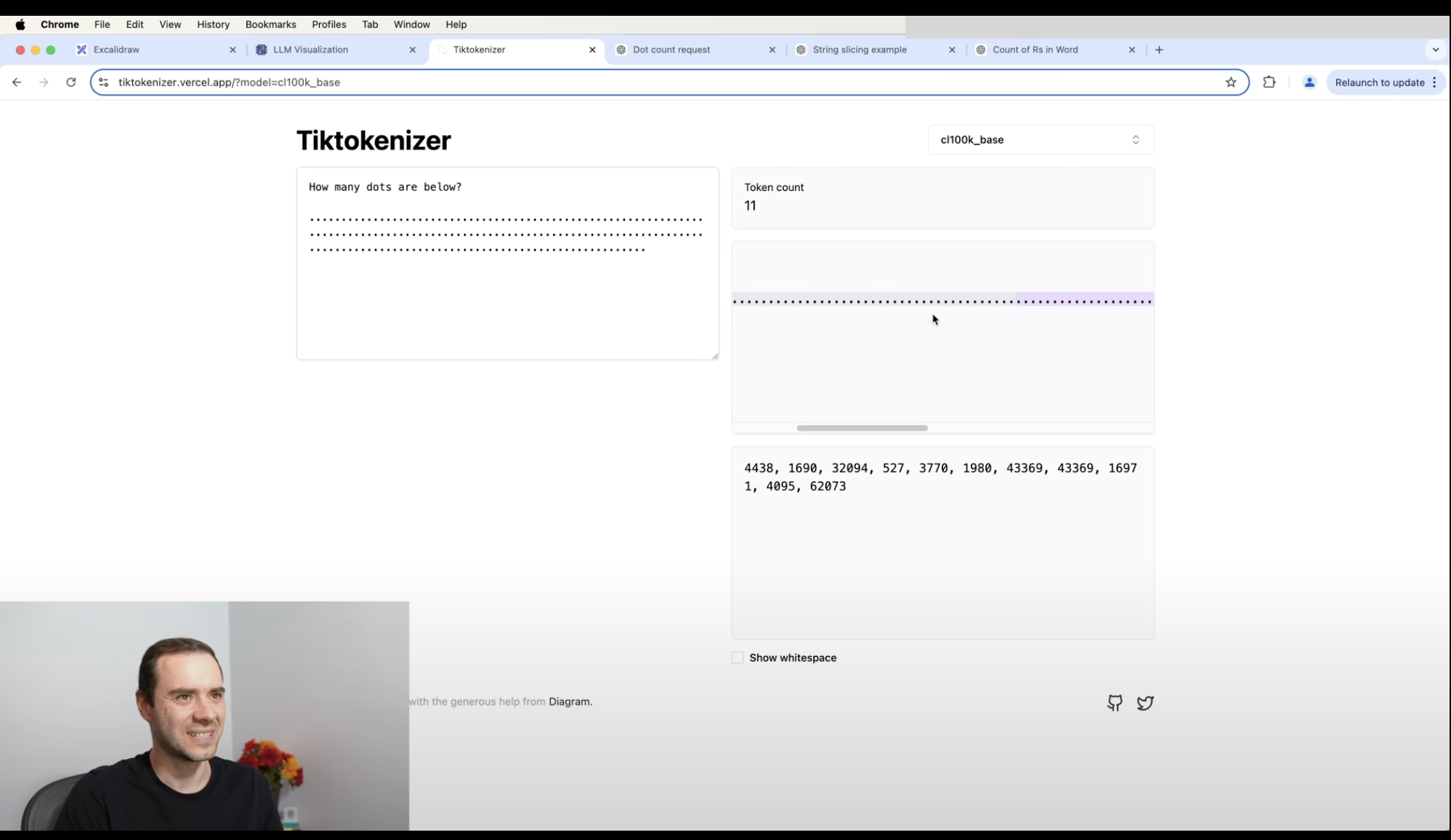 The dots example illustrates a fundamental limitation: when we show the model “………………………”, it sees this as just 3 tokens, making accurate counting impossible.
The dots example illustrates a fundamental limitation: when we show the model “………………………”, it sees this as just 3 tokens, making accurate counting impossible.
However, if we allow the model to use code, it can perform exact counting by copying and processing the input programmatically.
Character-Level Processing
A classic example that went viral was counting the number of ‘r’s in “strawberry”. This combines two challenges for models:
- Counting (which we discussed above)
- Character-level processing (as tokens group characters together)
4. Reinforcement Learning
RL represents the current frontier of the field .With supervised learning alone, you can at best reach human expert performance. RL, however, can discover entirely new approaches and surpass human expertise. This has already been demonstrated with AlphaGo, when with “move 37”, it discovered a novel move that no human would have played, despite its low probability of success, and AI got to be the best player in the world. We’re now just beginning to see similar breakthroughs with LLMs.
4.1 Learning Approaches
Here’s an analogy comparing RL to traditional learning from textbooks:
- Reading (Background Knowledge)
- Textbook: Reading chapters
- LLMs: Pre-training stage
- Guided Practice
- Textbook: Problems with solutions
- LLMs: Supervised fine-tuning with expert data
- Independent Practice
- Textbook: Solving new problems
- LLMs: Reinforcement learning (discovering solutions solving new problems via trial and error)
When creating training data, even as a labeler, it’s hard to know which solution approach is best for the model. What’s easy for humans isn’t necessarily easy for the model, and vice versa. If we only care about getting the correct answer, it makes more sense to let the LLM discover which token sequences work best for it.
We can:
- Sample thousands of possible solutions that lead to the correct answer
- Encourage the model to find the optimal approach

The way to encourage this is to train on the most successful sequences. Instead of using human-annotated solutions, we let the model explore through sampling and then train on the best sequences.
The SFT (Supervised Fine-Tuning) step remains valuable as it initializes the model to discover solutions efficiently.
In short, we train AI similarly to how we educate children with books, but with key differences:
- Pre-training: Process the entire book simultaneously
- SFT: Review all solutions
- Practice: Work through the entire book
4.2 Current State
The RL stage isn’t yet standardized in the field (unlike other stages).
Many companies (including OpenAI) have experimented with RL fine-tuning but haven’t published their findings. DeepSeek-R1, however, has released a paper showing impressive results.

For example, their AIME accuracy on Math problems (AIME Problems) demonstrates RL’s potential.
An interesting observation is that later in the optimization process, the model learns to generate more tokens to reach the correct answer. The model discovers that trying multiple approaches and re-evaluating is an effective strategy. This emerges naturally as a behavior - the model is learning how to think.
In OpenAI’s reasoning model series, they don’t show the chain of thought to reduce model distillation risks (preventing other models from training on their generated data).
4.3 Beyond Human Thinking
Continuing RL training at scale could unlock new possibilities and ways for models to solve problems.
This requires:
- Many practice problems
- Diverse domains
- Extensive iteration
4.4 Learning in Unverified Domains
When we don’t have clear answers, we can use an LLM as a judge to score the RL work. However, this approach has limitations in truly unverified domains.
Example: “Write a joke about Pelicans”
There’s no objective way to score the joke. While we could use human judges, RL requires thousands of iterations, each needing thousands of outputs to be scored. We need an automated approach.
RLHF Approach This approach was introduced in the RLHF OpenAI paper.
The process:
- Use humans to score initial outputs
- Train a Reward model to imitate human scoring
- Use this Reward model as a simulator of human preferences
- Train the RL model using this reward model
In practice, humans typically rank outputs rather than score them directly. The reward model takes the prompt and candidate response as input, outputting a score. It learns by comparing its rankings to human-provided rankings.
RLHF Considerations
Advantages:
- Enables RL in unverified domains
- Empirically improves model performance
- Leverages the discriminator-generator gap (humans find it easier to judge than create, allowing for incremental improvements) [Example: Writing poetry vs. Choosing the better poem]
Disadvantages:
- Relies on a simplified simulation of human preferences
- Vulnerable to reward hacking (the model may find ways to get high scores without actually improving)
- Can’t be run indefinitely without the model learning to game the system
RLHF is therefore more like fine-tuning than true RL - it can’t fundamentally transform the field.
5. Future and Practical Aspects
5.1 Future Developments
- Multi-modal models (audio, images, video, etc.)
- Task-oriented agents (long-running, coherent, self-correcting)
- Pervasive and invisible integration
- Computer-using capabilities for agents
- Test-time training innovations needed
5.2 Staying Informed
- Follow lmarena (LLM leaderboard based on human comparisons)
- Subscribe to AI News
- Follow relevant discussions on X/Twitter
5.3 Running Models
- Open weights: Together AI
- Base models: Hyperbolic
- Local deployment: LM Studio
6. Conclusion
We’ve explored what happens when we type a query into ChatGPT:
- Processing Flow:
- Query → Tokenizer → Token sequence
- Token sequence → Forward pass → Output (iterative)
- Training Stages:
- Pre-training (internet knowledge)
- Supervised fine-tuning (human labeler simulation)
- Cognitive capabilities (including limitations)
- Reinforcement learning (practice and improvement)
- Key Points:
- Models are essentially imitating human labelers
- RL shows promise but is still emerging
- Models excel in verifiable domains
- Never trust models blindly - use them as tools
The field is rapidly evolving and it is very exciting to be part of it! :D