Context Engineering: Single vs. Multi-Agent Systems
There’s a growing discussion in the AI community on how to build reliable and capable agents. A recent blog post from Cognition AI argues that the key lies in “Context Engineering”.
In 2025, the models out there are extremely intelligent. But even the smartest human won’t be able to do their job effectively without the context of what they’re being asked to do. “Prompt engineering” was coined as a term for the effort needing to write your task in the ideal format for a LLM chatbot. “Context engineering” is the next level of this. It is about doing this automatically in a dynamic system. It takes more nuance and is effectively the #1 job of engineers building AI agents.
I like this term better. It captures more accurately the daily effort going into making AI agent systems work, which involves setting up retrieval, memory management, context summarization, context forgetting, and much more.
The author suggests that the current state of agent development is similar to the early days of the web.
In the age of LLMs and building AI Agents, it feels like we’re still playing with raw HTML & CSS and figuring out how to fit these together to make a good experience. No single approach to building agents has become the standard yet, besides some of the absolute basics.
To build more reliable agents, the post proposes two principles for “Context Engineering”:
Principle 1 Share context, and share full agent traces, not just individual messages
Principle 2 Actions carry implicit decisions, and conflicting decisions carry bad results
Following these principles, the simplest and most reliable architecture is a single-threaded linear agent.

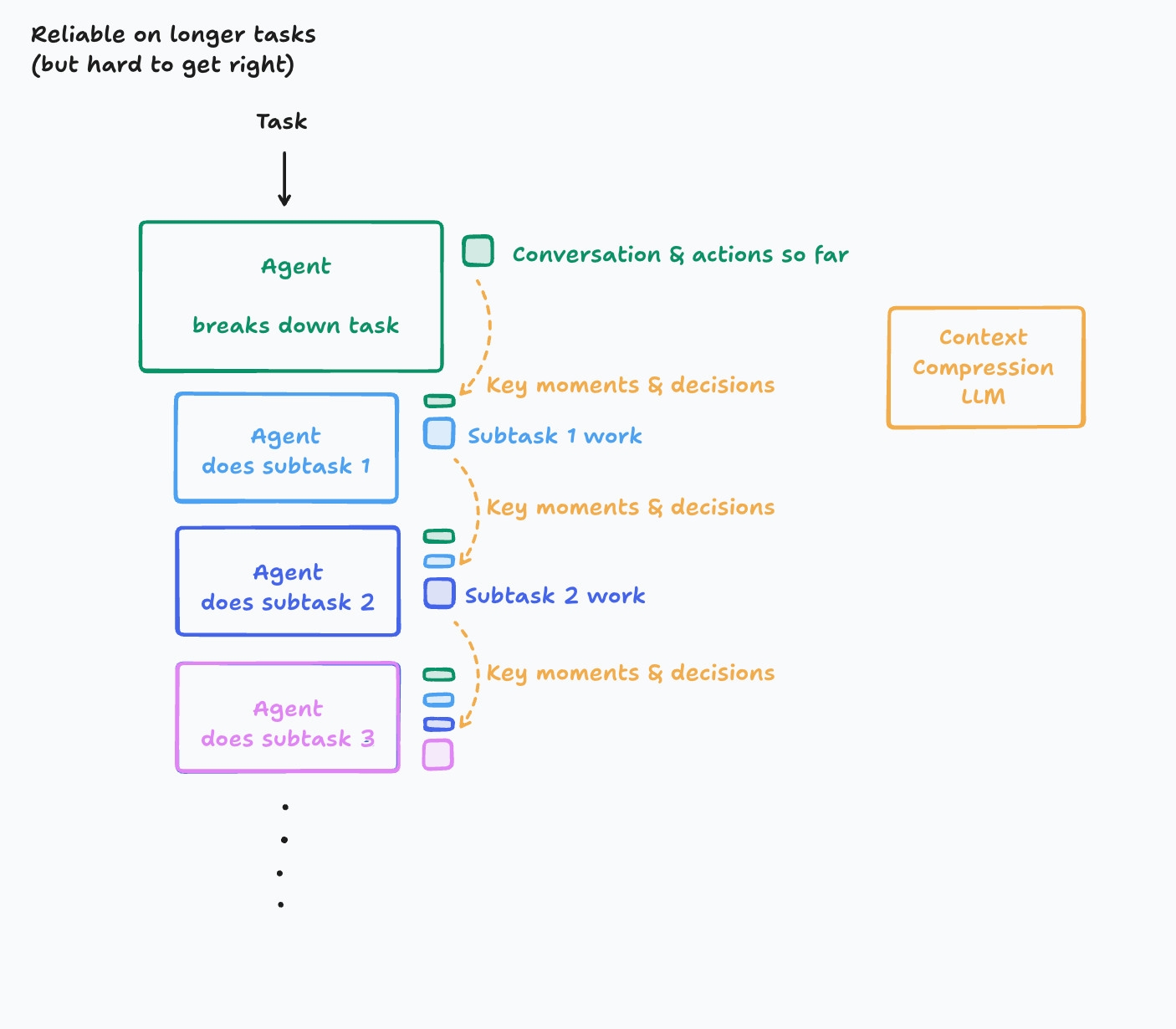
For longer tasks, the post suggests a more advanced, albeit harder to implement, architecture involving a “Context Compression LLM” to manage the growing context.
In this world, we introduce a new LLM model whose key purpose is to compress a history of actions & conversation into key details, events, and decisions. This is hard to get right. It takes investment into figuring out what ends up being the key information and creating a system that is good at this.
This leads to a skeptical view on multi-agent systems, which are seen as inherently fragile.
While I’m optimistic about the long-term possibilities of agents collaborating with one another, it is evident that in 2025, running multiple agents in collaboration only results in fragile systems. The decision-making ends up being too dispersed and context isn’t able to be shared thoroughly enough between the agents
The article provides some real-world examples of these principles:
Claude Code Subagents As of June 2025, Claude Code is an example of an agent that spawns subtasks. However, it never does work in parallel with the subtask agent, and the subtask agent is usually only tasked with answering a question, not writing any code. Why? The subtask agent lacks context from the main agent that would otherwise be needed to do anything beyond answering a well-defined question. And if they were to run multiple parallel subagents, they might give conflicting responses, resulting in the reliability issues we saw with our earlier examples of agents. The benefit of having a subagent in this case is that all the subagent’s investigative work does not need to remain in the history of the main agent, allowing for longer traces before running out of context. The designers of Claude Code took a purposefully simple approach.
Edit Apply Models In 2024, many models were really bad at editing code. A common practice among coding agents, IDEs, app builders, etc. (including Devin) was to use an “edit apply model.” The key idea was that it was actually more reliable to get a small model to rewrite your entire file, given a markdown explanation of the changes you wanted, than to get a large model to output a properly formatted diff. So, builders had the large models output markdown explanations of code edits and then fed these markdown explanations to small models to actually rewrite the files. However, these systems would still be very faulty. Often times, for example, the small model would misinterpret the instructions of the large model and make an incorrect edit due to the most slight ambiguities in the instructions. Today, the edit decision-making and applying are more often done by a single model in one action.
However, a different perspective comes from Anthropic. In a recent post on their multi-agent research system, they share impressive results with a multi-agent architecture.
Our internal evaluations show that multi-agent research systems excel especially for breadth-first queries that involve pursuing multiple independent directions simultaneously. We found that a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2% on our internal research eval.
This suggests that for certain types of problems, a multi-agent approach is not only viable but superior. The Anthropic team also touches upon the crucial topic of evaluation for these complex systems.
Because we don’t always know what the right steps are, we usually can’t just check if agents followed the “correct” steps we prescribed in advance. Instead, we need flexible evaluation methods that judge whether agents achieved the right outcomes while also following a reasonable process… We often hear that AI developer teams delay creating evals because they believe that only large evals with hundreds of test cases are useful. However, it’s best to start with small-scale testing right away with a few examples, rather than delaying until you can build more thorough evals.
The contrast between these two perspectives highlights that we are still in the early days of understanding how to best build and evaluate AI agents. While single-agent systems might offer more reliability for now, multi-agent systems seem to hold the key to unlocking new capabilities, provided we can solve the challenges of coordination, context sharing, and evaluation.